Code
library(tidyverse)
library(dplR)
library(hydroTSM)
library(zoo)Very often one wants to smooth or filter data to analyze or work only with particular aspects of the data. This kind of analysis is a big deal in time-series analysis. Smoothing is a way of isolating different frequencies of data but still thinking in the time domain.
You will want the dplR (Bunn et al. 2026) package – a subtle work of staggering genius – as well as zoo (Zeileis et al. 2025) and hydroTSM (Mauricio Zambrano-Bigiarini 2026).
library(tidyverse)
library(dplR)
library(hydroTSM)
library(zoo)Recall the very simple moving average filters we made earlier in class? Let’s revisit. People who work with time series are forever adding smooth lines to their plots in order to highlight signal and de-emphasize noise. It’s like a sickness. And everybody has a different way of doing it. We already looked at moving averages using the filter() function. Let’s just take a quick peek at some other common ones.
We’ve been using a lot simulated data, which is something I really like to do. It’s good for setting up situations where we want to see if we understand how a method works. But let’s use some tree-ring data this time to demonstrate a few different smoothing options.
This is a tree-ring chronology from near the arctic treeline in Canada that is one of the onboard data sets in dplR. I’ve pulled out the years for plotting.
data(cana157)
dat <- tibble(yrs = time(cana157), Z = scale(cana157[,1]))
nyrs <- nrow(dat)
p1 <- ggplot() +
geom_hline(yintercept = 0) +
geom_line(data=dat, mapping = aes(x=yrs,y=Z), color = "grey") +
labs(x="Year",y="Tree Growth (Z-Score)",
title="Twisted Tree Heartrot Hill Tree-Ring Chronology") +
theme_minimal()
p1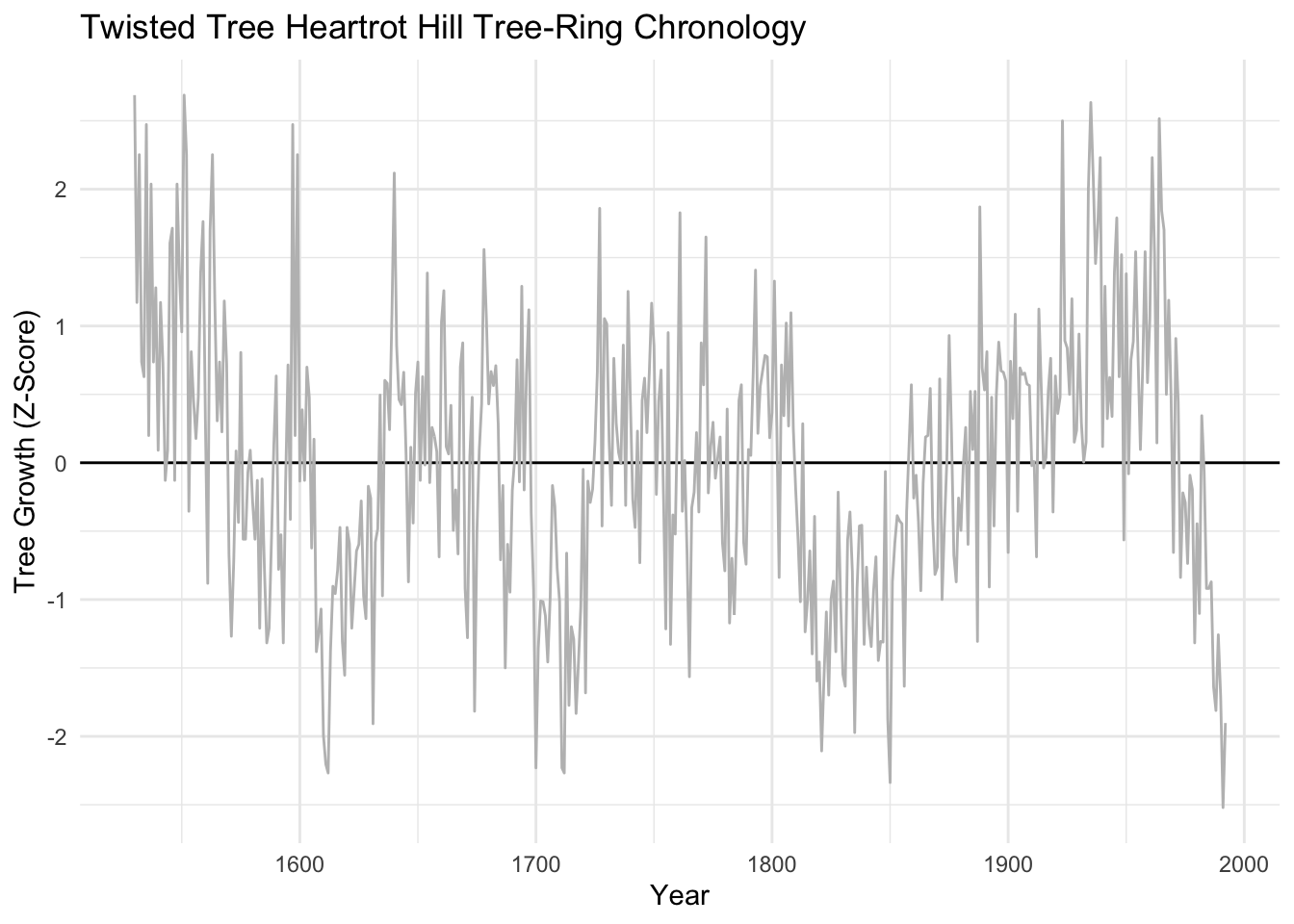
We’ve already looked at moving averages (aka running averages). Let’s revisit. These have the advantage of being dirt simple. Below we will see that they definitely emphasize low frequency in the examples below (at 20, 50, and 100 years) but retain some jaggedness too.
sfPal <- PNWColors::pnw_palette(name="Starfish",n=3,type="discrete")
dat <- dat %>%
mutate(ma20 = c(stats::filter(x=Z, filter=rep(x=1/20,times=20), sides=2)),
ma50 = c(stats::filter(x=Z, filter=rep(x=1/50,times=50), sides=2)),
ma100 = c(stats::filter(x=Z, filter=rep(x=1/100,times=100), sides=2)))
p1 + labs(subtitle = "Moving Average Filters") +
geom_line(data=dat, mapping = aes(x=yrs,y=ma20), color = sfPal[1],linewidth=1) +
geom_line(data=dat, mapping = aes(x=yrs,y=ma50), color = sfPal[2],linewidth=1) +
geom_line(data=dat, mapping = aes(x=yrs,y=ma100), color = sfPal[3],linewidth=1)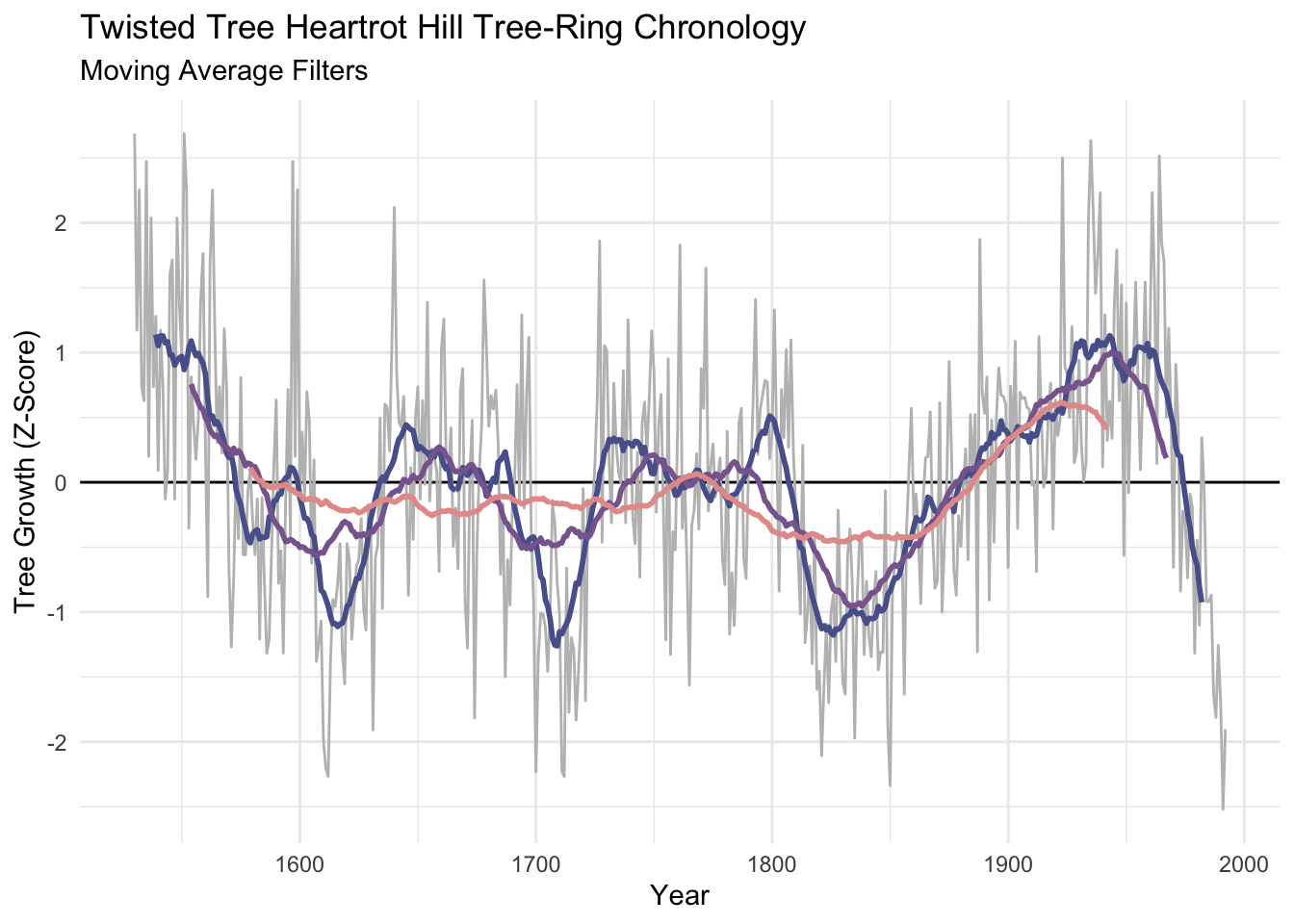
The Hanning filter is similar to the moving average in the sense that the curve emphasizes low frequency variability and loses the jaggedness over the moving average. It’s also a simple filter (look at the code by typing hanning at the R prompt) but it is a start into thinking in the frequency domain. It’s part of a family of functions called window functions that are zero-valued outside of some interval chosen by the user. It’s used quite a bit by time-series wonks and it is implemented in dplR with the function hanning(). I’ll skip the theory here but it’s a great precursor to the work we will do with spectral analysis next week.
dat <- dat %>%
mutate(han20 = hanning(Z,n=20),
han50 = hanning(Z,n=50),
han100 = hanning(Z,n=100))
p1 + labs(subtitle = "Hanning Filters") +
geom_line(data=dat, mapping = aes(x=yrs,y=han20), color = sfPal[1],linewidth=1) +
geom_line(data=dat, mapping = aes(x=yrs,y=han50), color = sfPal[2],linewidth=1) +
geom_line(data=dat, mapping = aes(x=yrs,y=han100), color = sfPal[3],linewidth=1)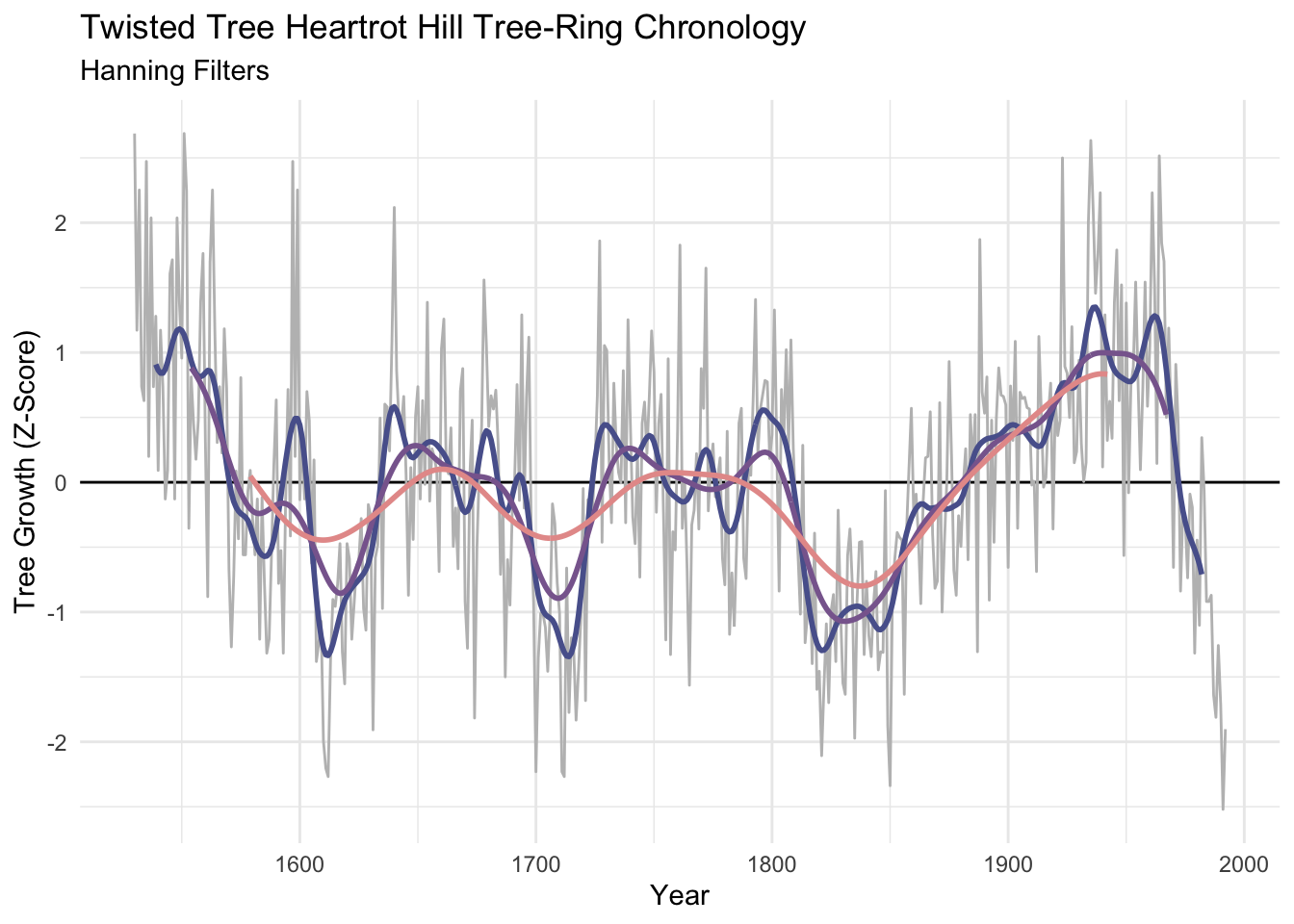
Like the moving average the smooth is shorter than the input data. It’s too bad because its nice to preserve the ends of the data but there is much wringing of hands and gnashing of teeth about the “right” way of running a smoothing algorithm where the data are sparse. This so-called end-member problem is the subject of a lot of work in the time-series literature.
Let’s look at dat. Here are the first 75 rows in a sortable table.
DT::datatable(round(dat,2),options = list(pageLength = 75))The function smooth.spline() fits a smooth curve to a set of observations using piecewise polynomials. Splines are used very commonly in time-series work both for smoothing and interpolating. We will look at interpolation below. The spar parameter is the one you can play with in smooth.spline(). Larger numbers smooth the data more heavily. Sadly the spar doesn’t translate into time units very easily.
dat <- dat %>%
mutate(ss0.2 = smooth.spline(Z,spar=0.2)$y,
ss0.4 = smooth.spline(Z,spar=0.4)$y,
ss0.6 = smooth.spline(Z,spar=0.6)$y)
p1 + labs(subtitle = "Smoothing Spline Filters") +
geom_line(data=dat, mapping = aes(x=yrs,y=ss0.2), color = sfPal[1],linewidth=1) +
geom_line(data=dat, mapping = aes(x=yrs,y=ss0.4), color = sfPal[2],linewidth=1) +
geom_line(data=dat, mapping = aes(x=yrs,y=ss0.6), color = sfPal[3],linewidth=1)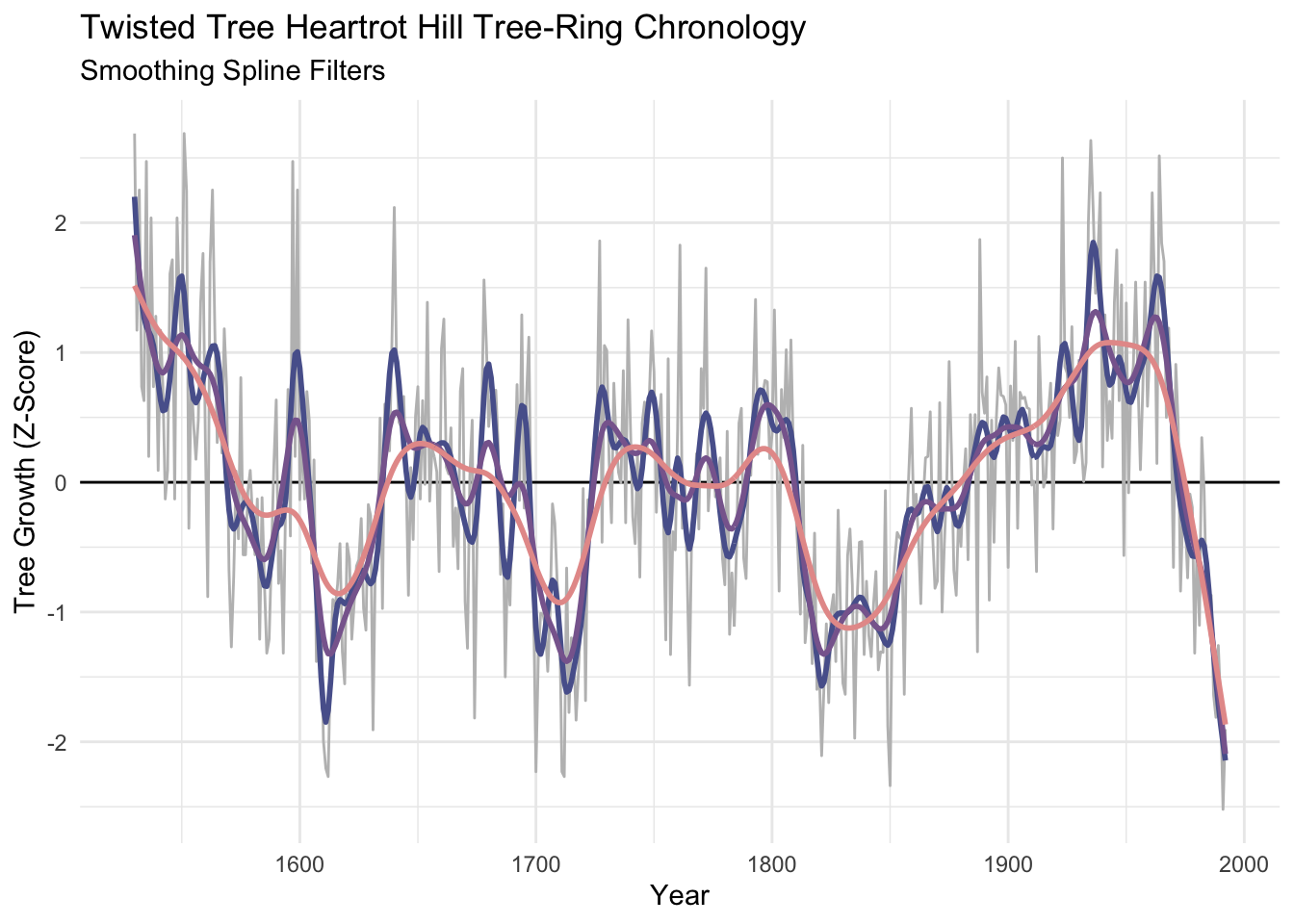
I’ve become increasingly fond of the loess smoother which uses a local, linear polynomial fit to smooth data. The parameter to adjust is the span span. Because span is the proportion of points used in the smoothing, the smaller the number the stiffer the curve will be. So a span of 0.05 would use 5% of the points. We can make the curves similar to the number of years in our moving average or hanning filters with some division.
dat <- dat %>%
mutate(f20.lo = loess(Z~yrs, span = 20/nyrs)$fitted,
f50.lo = loess(Z~yrs, span = 50/nyrs)$fitted,
f100.lo = loess(Z~yrs, span = 100/nyrs)$fitted)
p1 + labs(subtitle = "Loess Filters") +
geom_line(data=dat, mapping = aes(x=yrs,y=f20.lo), color = sfPal[1],linewidth=1) +
geom_line(data=dat, mapping = aes(x=yrs,y=f50.lo), color = sfPal[2],linewidth=1) +
geom_line(data=dat, mapping = aes(x=yrs,y=f100.lo), color = sfPal[3],linewidth=1)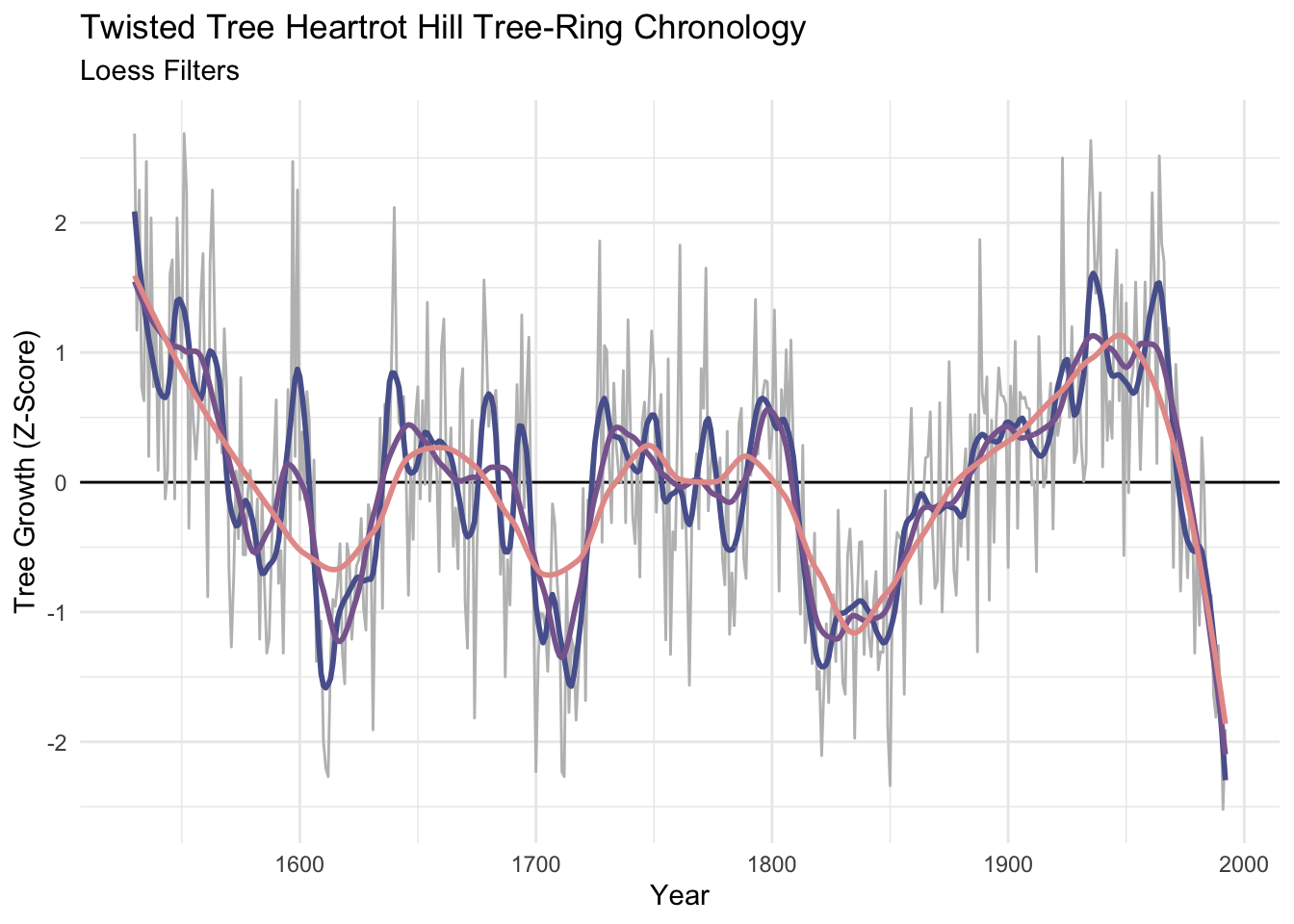
Unlike the moving averages and hanning filters, the smooth is the same length as the input data. That’s nice…but preserving the ends of the data means that there is less information at play on the ends than there is in the middle. There is no way to model the ends members to everybody’s satisfaction.
Let’s look at dat again.
DT::datatable(round(dat,2),options = list(pageLength = 75))The work above shows how to look at a time series at lower frequencies – it was eye candy. But what if we wanted to use those filters in some kind of analytic way? Here are some examples.
Sometimes you have data at one resolution but want it at another (coarser) resolution. E.g., you have hourly counts of fish escapement but want to sum up the hours in a day to get the total fish per day or average it to get fish per hour. We’ve done this already but here is an example worth revisiting.
Let’s go back to the Bellingham airport data. The file kbliMonthlyTavg.rds contains a zoo object with monthly average temperatures from Bellingham. We will use filter, rollmean, and dmseasonalto get summer temperature. Here are three ways of doing the same thing. I’ll work with ts, and zoo objects. And pull in the dm2seasonal function from the wonderful hydroTSM package.
tavgZoo <- readRDS("data/kbliMonthlyTavg.rds")
tavgTS <- ts(tavgZoo,start=c(1941,1),frequency = 12)
# let's look at a few years
plot(window(tavgTS,start=2000, end = 2004),
ylab=expression(degree*C))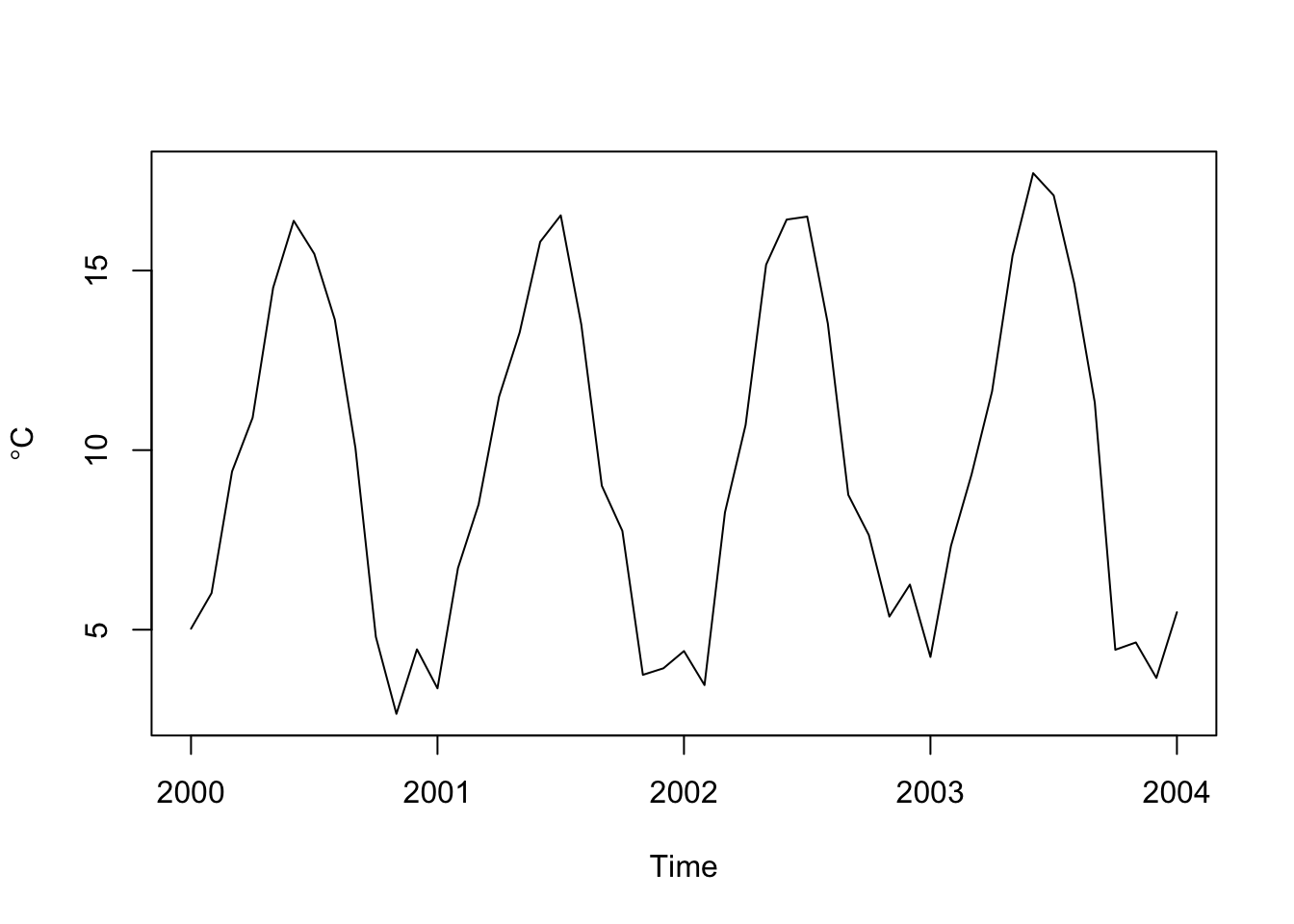
# get summer (JJA) temps three ways
# 1. using filter on a ts object
tmp <- stats::filter(tavgTS, rep(1/3,3), sides = 1)
summerTavg_v1 <- tmp[seq(8,length(tmp),by=12)]
# 2. using zoo -- essentially the exact same as above
tmp <- rollmean(tavgZoo,k=3, align = "right")
summerTavg_v2 <- tmp[months(time(tmp)) == "August"]
# 3. using hydroTSM
summerTavg_v3 <- hydroTSM::dm2seasonal(tavgZoo,season="JJA",FUN=mean)
# note they are all the same
head(summerTavg_v1)[1] 15.71615 16.04912 14.60194 15.79032 14.75443 15.26229head(summerTavg_v2)1941-08-01 1942-08-01 1943-08-01 1944-08-01 1945-08-01 1946-08-01
15.71615 16.04912 14.60194 15.67921 15.10165 15.42063 head(summerTavg_v3) 1941 1942 1943 1944 1945 1946
15.71615 16.04912 14.60194 15.67921 15.10165 15.42063 # Looks like it is getting warmer.
plot(summerTavg_v2,ylab=expression(degree*C),xlab="Time")
abline(lm(summerTavg_v2~time(summerTavg_v2)),col="red")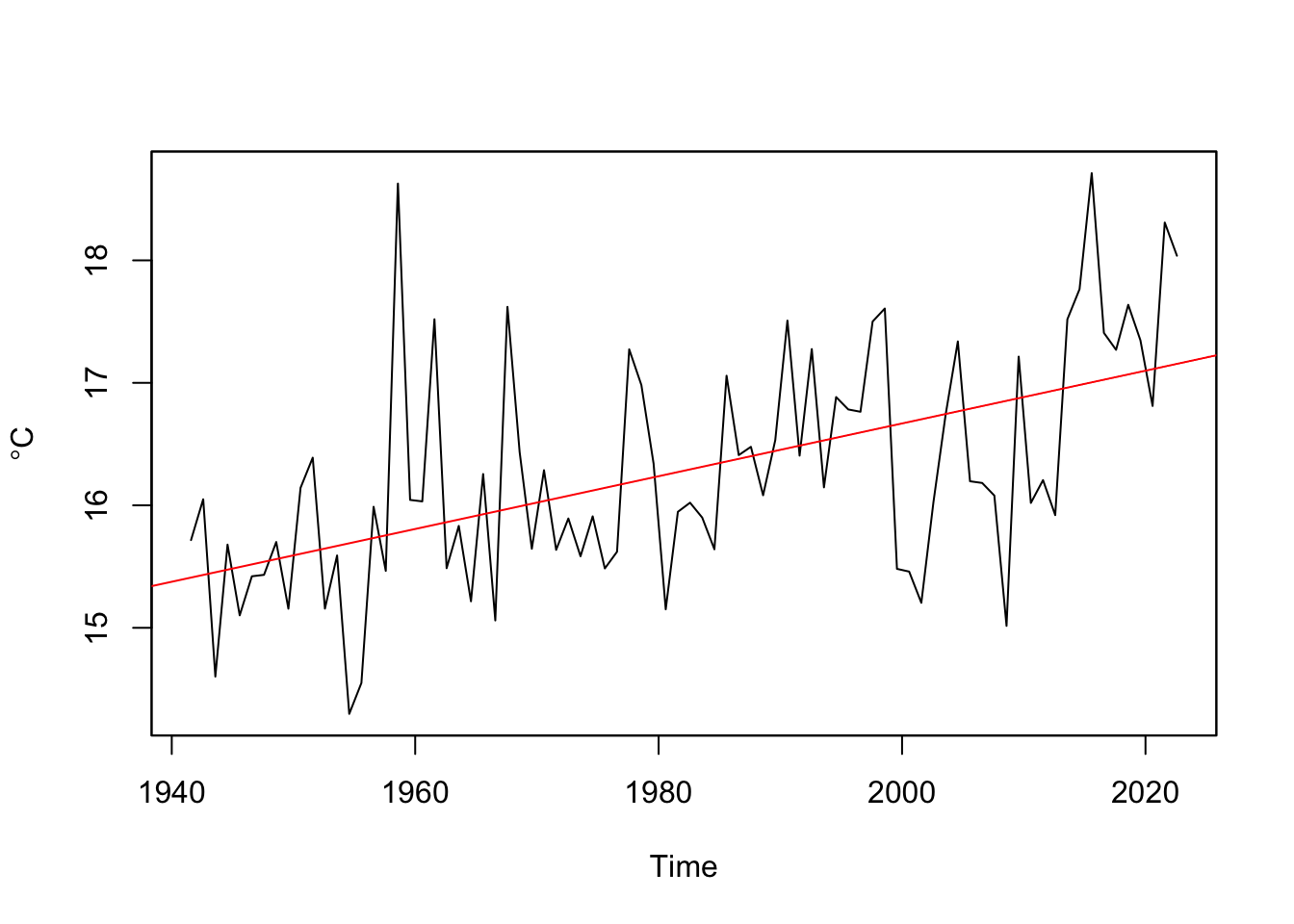
Go through the code and make sure you follow what just happened at each step.
Sometimes we use filters as visual aids that help us see certain aspects of the data. Other times we want to work only with low or high frequency data. A common way of removing some kinds of variability is to take residuals from a filter to remove, say, low-frequency variability.
For instance, a perennial problem in working with tree-ring data is the problem of detrending the biological growth curve from the signal that you usually want – the year-to-year variability caused by, say, plant available water. Smaller trees have larger rings solely as a function of geometry. This leads to a natural negative exponential decay in growth as the tree ages that has nothing to do with climate. We can remove that signal by fitting a loess curve and then taking the residuals via division (subtraction can be used too). Dendrochronologists call this the ring-width index.
data(co021)
core1 <- tibble(yr = time(co021), mm = co021$`641114`)
core1 <- core1 %>% drop_na()
core1# A tibble: 694 × 2
yr mm
<dbl> <dbl>
1 1270 1.48
2 1271 2.33
3 1272 1.32
4 1273 0.67
5 1274 0.82
6 1275 1.22
7 1276 0.52
8 1277 0.57
9 1278 0.4
10 1279 0.65
# ℹ 684 more rowsn <- nrow(core1)
ggplot(data=core1) +
geom_line(mapping = aes(x = yr, y = mm)) +
labs(x="Year", y = "Ring Width (mm)",
subtitle = "Sample 641114 Schulman Old Tree No. 1, Mesa Verde")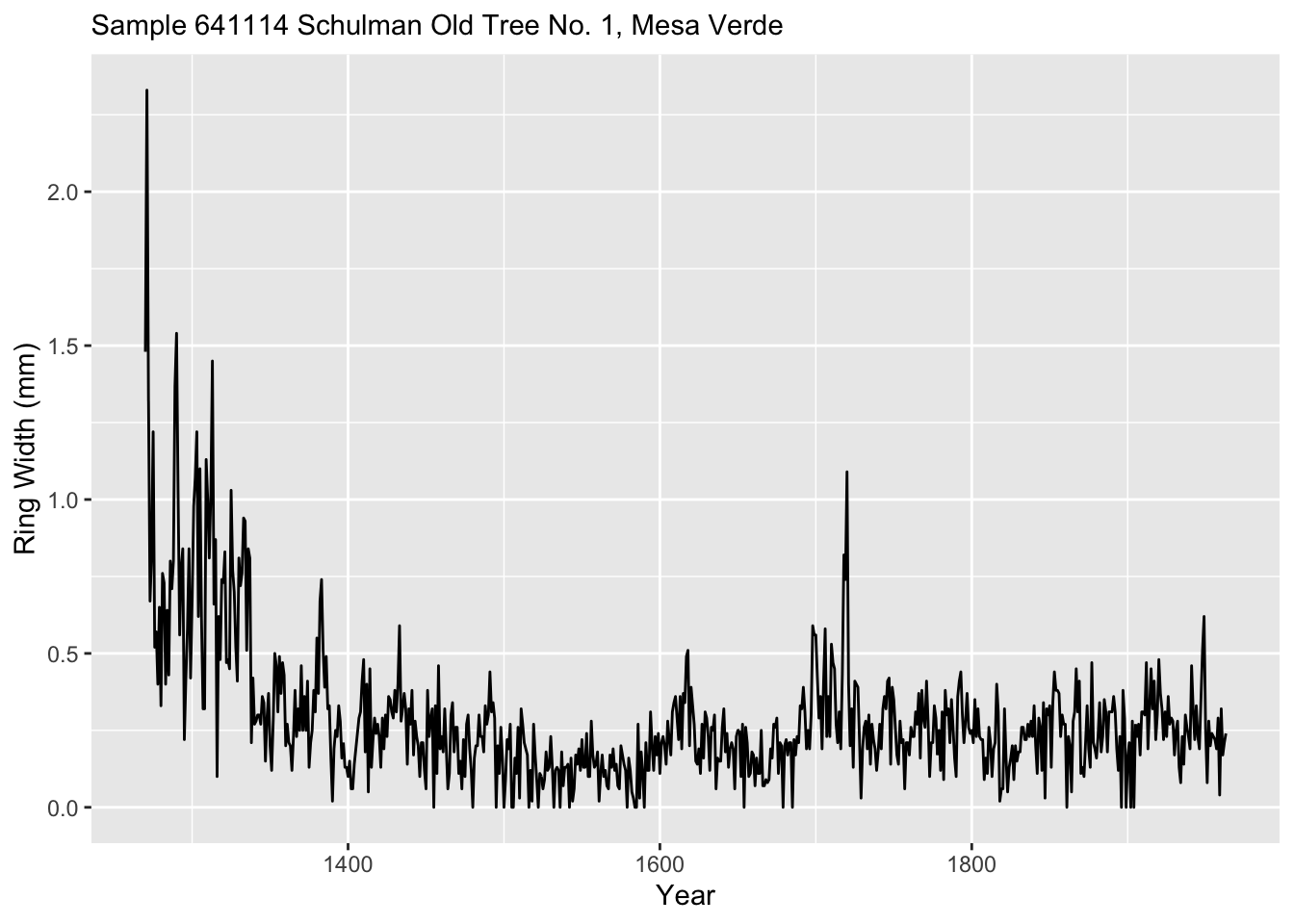
We will fit a loess model of ring wing width as a function of time. Note this is a first-order polynomial (degree = 1) while the default is to use a 2nd-order polynomial. The argument span gives the percentage of the points used. Since there are 694 this corresponds to 69 years being used at each fit.
loessModel <- loess(formula = mm ~ yr, data = core1, degree = 1, span = 0.05)
loessFit <- broom::augment(loessModel)Because the output object from loessModel model is, well, yucky, I used augment from broom to put it in a nicer format.
Here is a plot of the fit.
loessFit %>% ggplot() +
geom_line(mapping = aes(x = yr, y = mm), color="grey") +
geom_line(mapping = aes(x = yr, y = .fitted), color = "black") +
labs(x="Year", y = "Ring Width (mm)", caption = "5% loess smooth",
subtitle = "Sample 641114 Schulman Old Tree No. 1, Mesa Verde")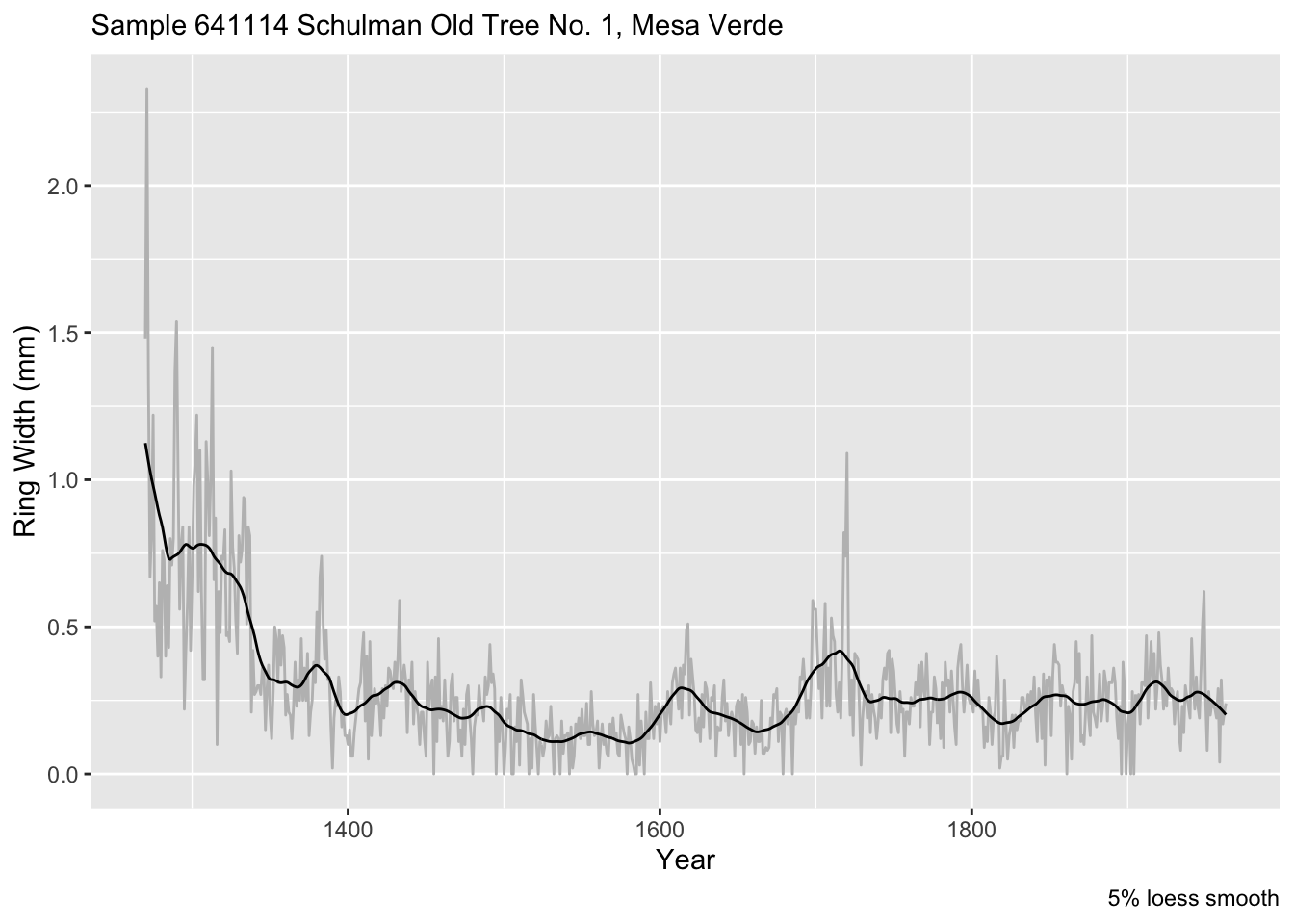
If instead of a proportion of the data, we can specify a number of points (years) to use like we did above. E.g., 100-year smooth. Is 100 years the right value? Nobody can really say. But this is one approach for filtering out this relatively low-frequency (100 period = 0.01 f).
loessModel <- loess(formula = mm ~ yr, data = core1, degree = 1, span = 100/n)
loessFit <- broom::augment(loessModel)
loessFit %>% ggplot() +
geom_line(mapping = aes(x = yr, y = mm), color="grey") +
geom_line(mapping = aes(x = yr, y = .fitted), color = "black") +
labs(x="Year", y = "Ring Width (mm)", caption = "100-year loess smooth",
subtitle = "Sample 641114 Schulman Old Tree No. 1, Mesa Verde")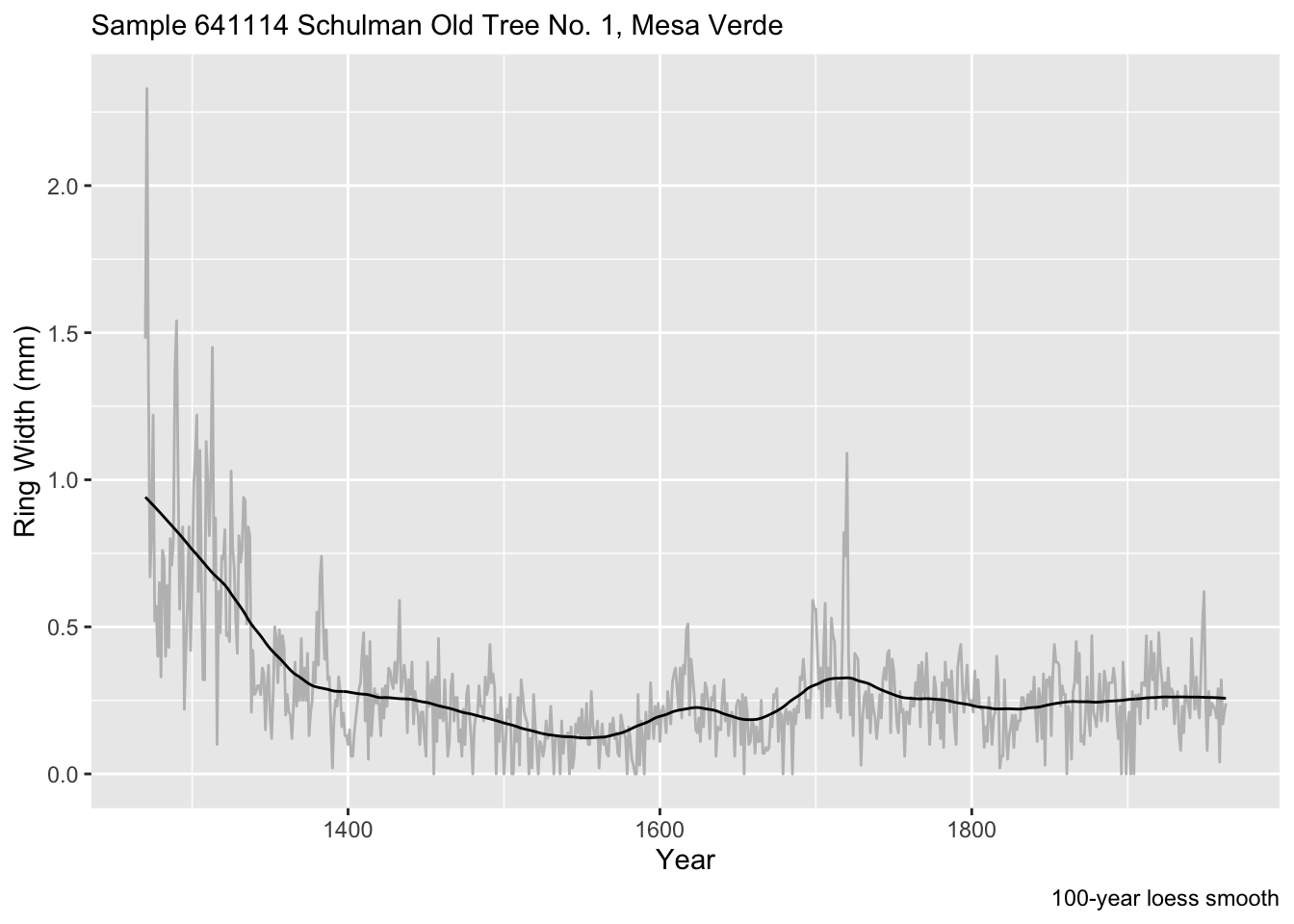
We can make the RWI via:
core1$rwi <- loessFit$mm/loessFit$.fitted
names(core1) <- c("Year", "Ring Width (mm)"," Ring Width Index (RWI)")
core1 %>% pivot_longer(cols=-Year) %>%
ggplot(mapping = aes(x = Year, y = value)) +
geom_line() +
labs(x="Year", y = element_blank(),
subtitle = "Sample 641114 Schulman Old Tree No. 1, Mesa Verde") +
facet_grid(rows=vars(name),scales = "free")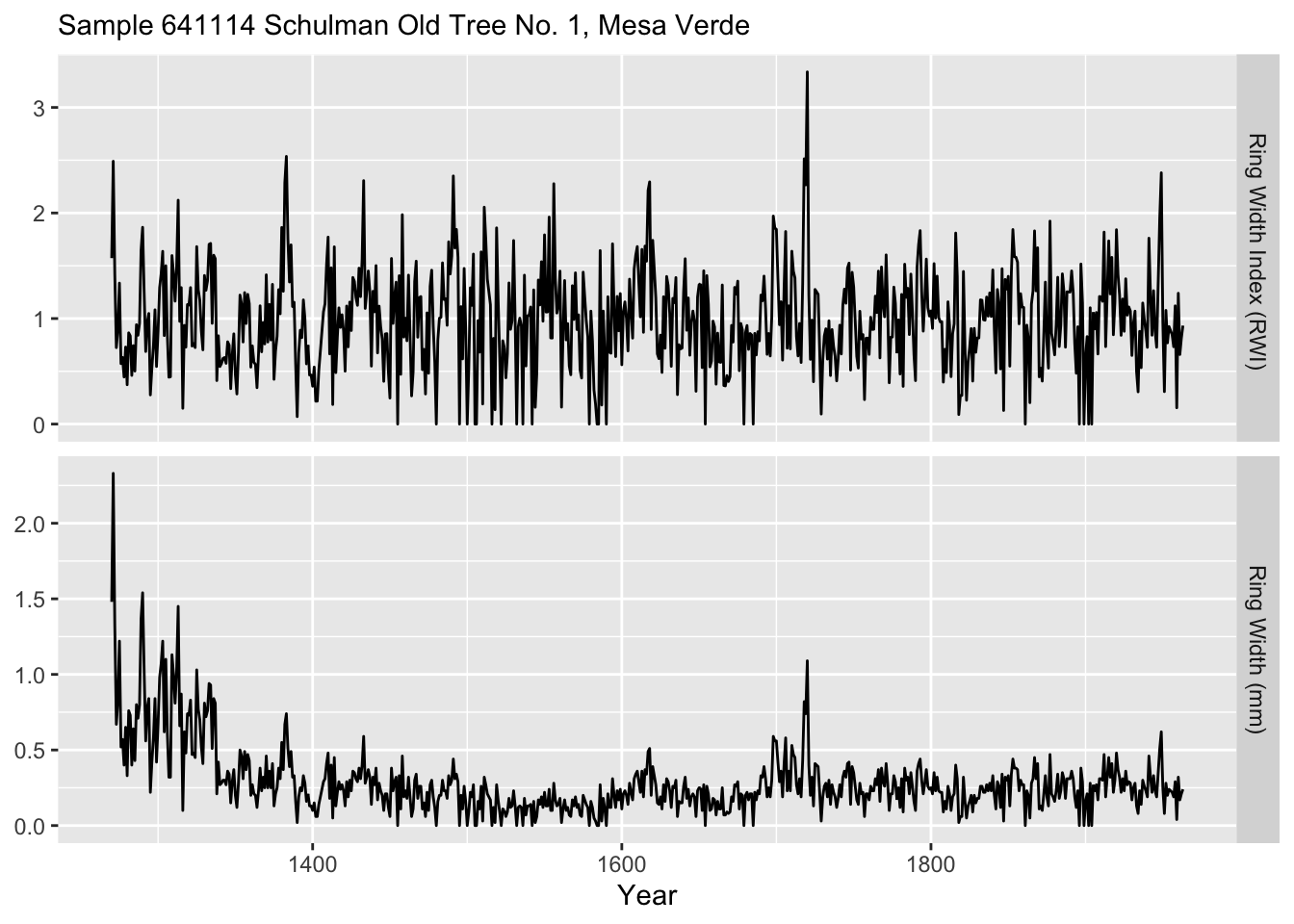
Let’s look at another use for filters. You have a critical bit weather data from a temperature logger and a solar radiation sensor that you inherited for your work. Your thesis, tenure packet, soul, whatever depend on faithful analysis. As is common with inherited data, you can’t control the quality. It turns out that these sensors were deployed by a hapless undergrad. The loggers were supposed to be deployed to record hourly over the summer of 2014. They were supposed to be launched synchronously on June 1 at midnight. Beware! The good-for-nothing adviser didn’t read the manual or spend enough time with the aforementioned undergrad. Regrettably, the temperature data started collecting at three minutes past the hour and collected every other hour. The radiation sensor was launched correctly but the cable wasn’t connected well enough and as a result there are a bunch of missing data over the summer.
Load the data in as two data.frame objects. Here is a summary and plot.
rad <- readRDS("data/rad.rds")
tmp <- readRDS("data/tmp.rds")
summary(tmp[,2]) Min. 1st Qu. Median Mean 3rd Qu. Max.
-5.818 7.889 10.490 10.537 13.432 21.640 summary(rad[,2]) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.0 0.0 49.5 280.0 530.0 1239.0 220 pTmp <- ggplot(tmp) +
geom_line(mapping = aes(x=DateTime,y=tmp)) +
labs(x="Date",y=expression(degree * C),
subtitle = "Air Temperature") +
theme_minimal()
pRad <- ggplot(rad) +
geom_line(mapping = aes(x=DateTime,y=rad)) +
labs(x="Date",y=expression(W~m^-2),
subtitle = "Radiation") +
theme_minimal()
gridExtra::grid.arrange(pTmp,pRad) 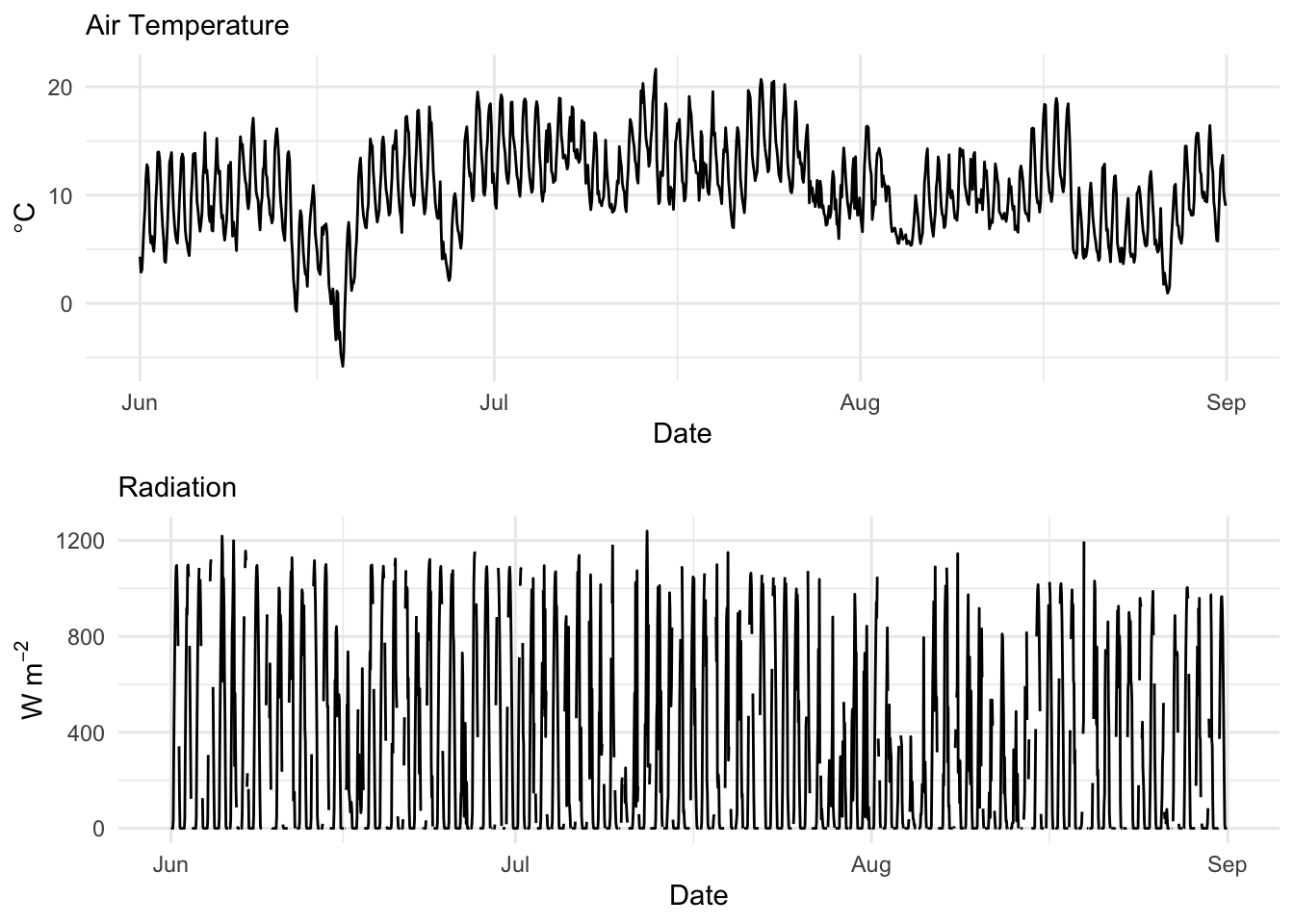
Here is a better look at the times:
head(tmp$DateTime)[1] "2014-06-01 00:03:00 UTC" "2014-06-01 02:03:00 UTC"
[3] "2014-06-01 04:03:00 UTC" "2014-06-01 06:03:00 UTC"
[5] "2014-06-01 08:03:00 UTC" "2014-06-01 10:03:00 UTC"head(rad$DateTime)[1] "2014-06-01 00:00:00 UTC" "2014-06-01 01:00:00 UTC"
[3] "2014-06-01 02:00:00 UTC" "2014-06-01 03:00:00 UTC"
[5] "2014-06-01 04:00:00 UTC" "2014-06-01 05:00:00 UTC"The times on the temperature data are pretty easy to fix. They are off by three minutes from what you wanted. Now three minutes is not a big deal. Let’s just snap those back to the hour. We can do that easily buy subtracting 180 seconds from each one. The dates and times in the temperature data.frame is a POSIXct object. Internally, these are a measure of seconds from an origin (usually January 1, 1970). Just subtract the requisite number of seconds:
tmp$DateTime <- tmp$DateTime - 180
head(tmp$DateTime)[1] "2014-06-01 00:00:00 UTC" "2014-06-01 02:00:00 UTC"
[3] "2014-06-01 04:00:00 UTC" "2014-06-01 06:00:00 UTC"
[5] "2014-06-01 08:00:00 UTC" "2014-06-01 10:00:00 UTC"Times are fixed. That was easy.
Ok. That was a fun excursion working with zoo. But let’s use filters to impute data gaps. About 10% of the data are missing on the radiation data.frame. Curses. Let’s interpolate it. First we will make it a zoo object and make a plot of the first 100 observations so we can see the problem more clearly.
zooRad <- zoo(rad[,2],rad[,1])
# let's look at the first 100 observations.
plot(zooRad[1:100],type="b",pch=20,ylab=expression(W~m^-2))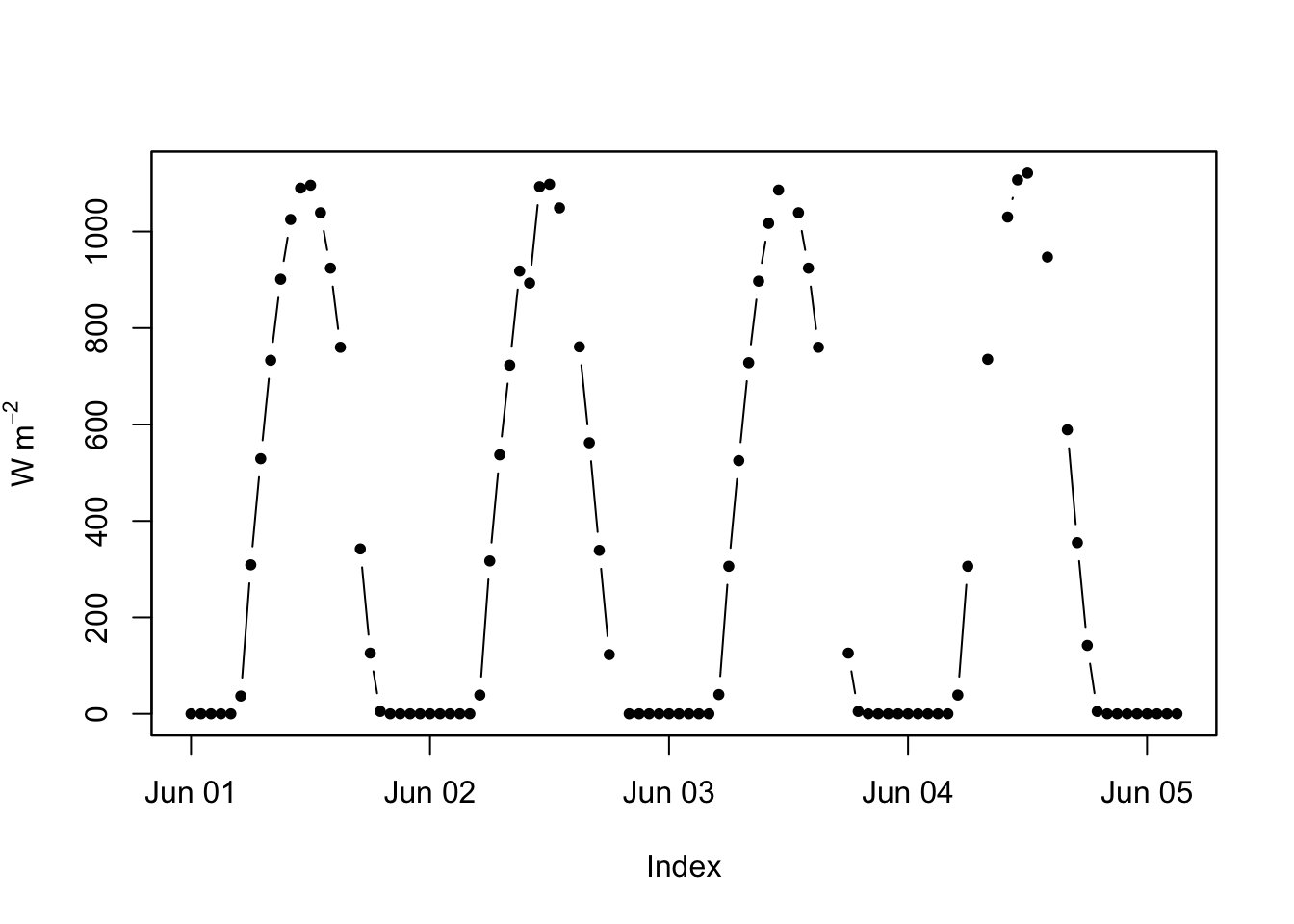
The zoo package has several ways of filling NA values. Let’s run a linear interpolation and a cubic smoothing spline. In this case, the results are very similar because the radiation data are quite well behaved (sun comes up and sun goes down).
zooRad.approx <- na.approx(zooRad)
zooRad.spline <- na.spline(zooRad)
plot(zooRad.approx[1:100],type="b",pch=20,ylab=expression(W~m^-2),col="blue",lwd=2)
lines(zooRad.spline[1:100],lwd=2,col="red",lty="dotted")
lines(zooRad[1:100],col="grey",lwd=1)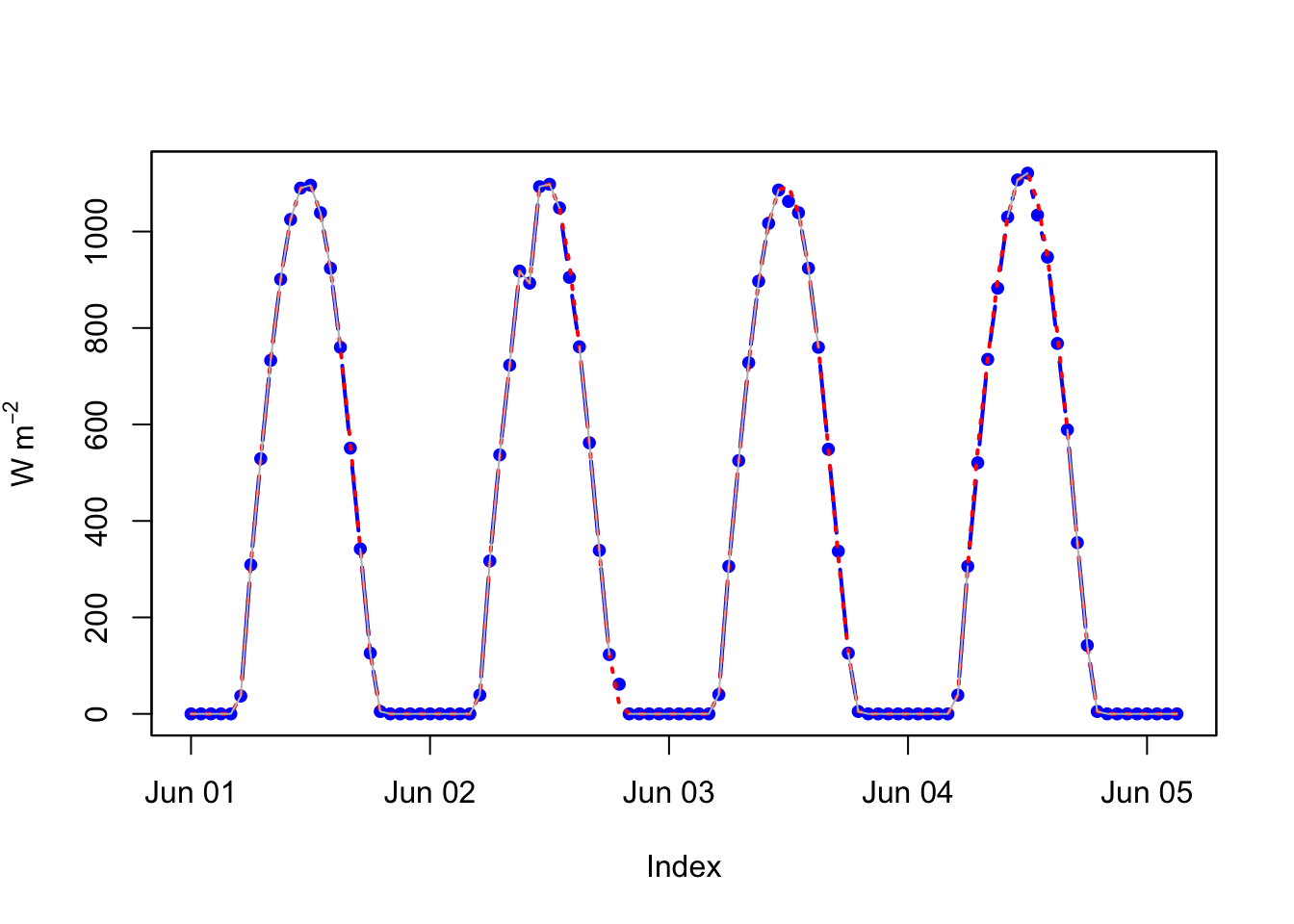
That was easy too. Note the different ways of filling in the missing data. Look at na.locf as well. They all use some kind of filtering to impute the missing data.
Fit some smooths to the data below. What’s looks good? What feels “right” in terms of a good filter?
n <- 500
dat <- tibble(x = 1:n,
y = c(arima.sim(model = list(order = c(2,0,1),
ar=c(0.7, -0.2), ma = -0.4),
n=n)))
dat$y <- dat$y +
0.3 * sin(2 * pi / 100 * dat$x) +
0.5 * sin(2 * pi / 200 * dat$x)
ggplot(data = dat,mapping = aes(x=x,y=y)) +
geom_line()
In the poorly launched sensors debacle there were a few problems. The radiation data was spotty but collecting every hour (2208 observations). The temp data was collecting every other hour (1104 observations) AND doing so at three minutes after the hour. We fixed the second part but not the first one. Your task is to align these data sets. They have to be hourly resolution for some reason you can invent. Figure out a way to take the tmp object above and change it to have hourly rather than two hourly resolution. I can think of several ways to do it but I’m going to leave you up to your own devices to figure out a way to do it. When you are done the radiation and temperature data should be aligned with 2208 observations each.
Pass in a R Markdown doc with your analysis. Leave all code visible, although you may quiet messages and warnings if desired. Turn in your knitted html. The last section of your document should include a reflection where you explain how it all went. What triumphs did you have? What is still confusing?